Today we're gonna dip our fingers into the first generative NLP task - text summarization. We're gonna use the CNN/Daily Mail dataset as done in this paper. Let's get to it.
Data prep
I started by doing all the preprocessing of the files myself, but then found a the dataset on hugging face. Even though preprocessing is a very important step, we'll make our life easier and focus on the models. After installing the datasets package, getting the dataset is as easy as calling
from datasets import load_dataset
ds = load_dataset("abisee/cnn_dailymail", "3.0.0")
The structure of the samples is
{
'article': 'LONDON, England (Reuters) -- Harry Potter star Daniel Radcliffe gains access to a reported £20 million ($41.1 million)...',
'highlights': "Harry Potter star Daniel Radcliffe gets £20M fortune as he turns 18 Monday .\nYoung actor says he has no plans to fritter his cash away .\nRadcliffe's earnings from first five Potter films have been held in trust fund .",
'id': '42c027e4ff9730fbb3de84c1af0d2c506e41c3e4'
}
The article will be fed to the model which will produce highlights in turn.
Next we need to tokenize the text. Again, making use of the comforts of modern deep learning
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
And we simply tokenize with
tokenizer(ds['train'][0]['article'])
Building a model
As a baseline we'll train a seq2seq RNN taken from the hugging face NLP translation tutorial. I haven't worked with RNNs before, and I know they are notorious for being hard to train, which is why transformers basically replaced them. Nevertheless, we're gonna start with it for lols and also out of curiosity, and move on to transformers eventually. The architecture we use is quite simple but also profound?
Quick Aside: Solving the variable length problem
Back to the architecture
Here's the code for the encoder:
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
SOS_token = tokenizer.special_tokens_map['bos_token']
SOS_token = tokenizer.vocab[SOS_token]
EOS_token = tokenizer.special_tokens_map['eos_token']
EOS_token = tokenizer.vocab[EOS_token]
MAX_LENGTH = 800
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, hidden = self.gru(embedded)
return output, hidden
The encoder gets the token indexes, replaces each one with an trainable embedding vector. During training the embeddings undergo dropout for regularization etc. The embeddings are then fed to the GRU block, which is a thing I should totally read more about, but for our purposes it produces the required output and hidden vectors. The syntax actually hides the sequential nature of the recurrence: each token is fed to the GRU, which produces an an output and a hidden state vector.
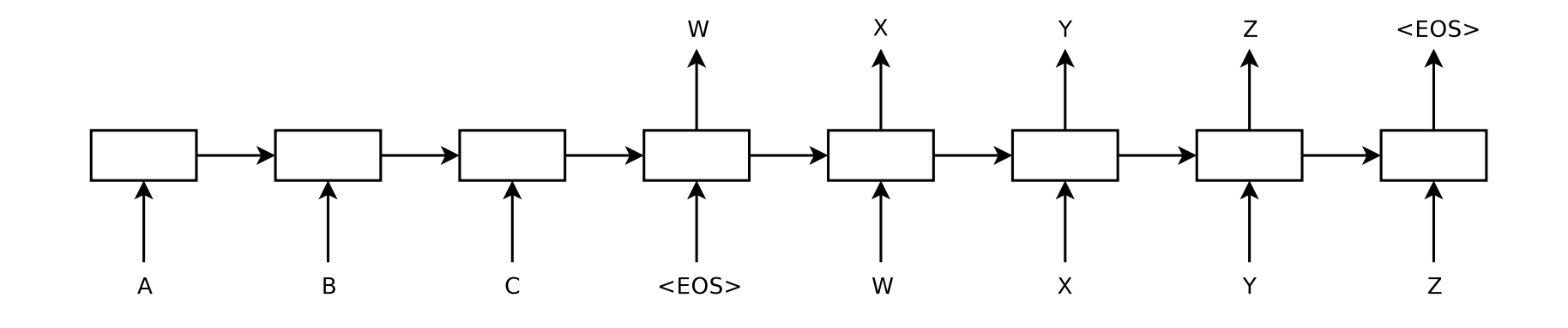
This hidden vector is then passed as input to the GRU activation on the next token, ie, if we wrote it by hand it would look something like
hidden = ? # TODO how do we initialize the hidden layer?
outputs, hiddens = [], []
for t in input:
embedded = embedding(t)
output, hidden = gru(embedded, hidden)
outputs.append(output); hiddens.append(hidden)
Anyway, the final product of the encoder is a fixed vector which encodes all the information about the text. The decoder then receives it as the hidden input and a special "start-of-sentence" token and sequentially outputs a probability distribution over the vocabulary for the next token. In order to terminate, it can output the "end-of-sentence" token (does it matter that it's the same?). Otherwise the decoder is similar to the decoder.
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
return decoder_outputs, decoder_hidden, None # We return `None` for consistency in the training loop
def forward_step(self, input, hidden):
output = self.embedding(input)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output)
return output, hidden
You might wonder why it appears more complicated if it's similar to the encoder. To answer that we need to consider the difference between training and inference, and the loss criterion we are using. I hope to get to that in a future post, so for now I'll just mention that we will use the cross-entropy loss, which tries to maximize the likelihood of the dataset.
Training loop
Steps: - Select hyperparams (hidden size, lr) and initialize model. - Probably need to add SOS and EOS tokens to summaries - batches, How to handle different length sequences? - monitoring the process
hidden_size = 1024
enc = EncoderRNN(len(tokenizer), hidden_size).to(device)
dec = DecoderRNN(hidden_size, len(tokenizer)).to(device)
from torch.utils.data import DataLoader
import torch.optim as optim
from tqdm import tqdm
lr = 0.001
enc_optimizer = optim.Adam(enc.parameters(), lr)
dec_optimizer = optim.Adam(dec.parameters(), lr)
loss_f = nn.NLLLoss()
train_dataloader = DataLoader(ds['train'], batch_size=1, shuffle=True)
epochs = 1
for e in range(epochs):
for i, data in tqdm(enumerate(train_dataloader)):
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
art, summ = data['article'], data['highlights']
art = torch.tensor(tokenizer(art)['input_ids']).to(device)
sum = torch.tensor(tokenizer(summ)['input_ids']).to(device)
enc_out, enc_hid = enc(art)
dec_out, _, _ = dec(enc_out, enc_hid, sum)
# loss
loss = loss_f(
dec_out.view(-1, dec_out.size(-1)),
sum.view(-1)
)
if i % 50 == 0:
print(loss)
loss.backward()
enc_optimizer.step()
dec_optimizer.step()
Tensors and variable length sequence
We used above a batch size of one. This isn't practical, since we aren't parallelizing anything, and training would take forever, but we have to overcome a technical problem: how do we put variable-length arrays of tokens into a tensor?
The first option is to extend the sequences in the batch to a maximum length, otherwise known as padding. This enables us to put all the sequences in one tensor, which let's PyTorch do things in parallel. We would just need to remember to extract the relevant output and hidden vectors from the step where the sequence actually ended (otherwise it would be garbage). We do the same thing for both encoder and decoder. As a padding value we can use a special endofsentence token.
There is a drawback with that though, as we're wasting "compute" on sequences which are already irrelevant. An improvement to that is to keep track which sequences haven't ended yet and only parallelize over them. PyTorch can take care of that using an abstraction called PackedSequence (packed sequence util). This interleaves all the different tensor into one 1-d array of data, together with information over how many sequences are in the next batch. For example,
pack_sequence([torch.tensor([1,2,3]), torch.tensor([4,5])])
produces
PackedSequence(data=tensor([1, 4, 2, 5, 3]), batch_sizes=tensor([2, 2, 1]), sorted_indices=None, unsorted_indices=None)
Sadly, while some layers like nn.GRU handle the PackedSequence data structure, others don't. Mainly, nn.embeddings require some attention, but a small modification suffices
def simple_elementwise_apply(fn, packed_sequence):
"""applies a pointwise function fn to each element in packed_sequence"""
return torch.nn.utils.rnn.PackedSequence(fn(packed_sequence.data), packed_sequence.batch_sizes)
# encoder
def forward(self, input):
...
if isinstance(input, PackedSequence):
embedded = simple_elementwise_apply(lambda x: self.dropout(self.embedding(x)), input)
else:
embedded = self.dropout(self.embedding(input))
Modifying the decoder is a bit trickier, but doable
def forward_teacher(self, decoder_input, decoder_hidden, target_packed):
i = 0
decoder_outputs = []
for batch_size in target_packed.batch_sizes:
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output[:batch_size])
decoder_input = target_packed.data[i:i + batch_size].unsqueeze(-1)
decoder_hidden = decoder_hidden[:, :batch_size, :]
i += batch_size
decoder_outputs = torch.nn.utils.rnn.PackedSequence(torch.cat(decoder_outputs), target_packed.batch_sizes)
return decoder_outputs
Finally, the training loop. Took me a long time to figure out a nice bug I introduced. Since packing requires sorting the different sequences in descending length, the articles and summaries get sorted differently. This means the batch output of the encoder needs to be sorted back to the original order and then sorted again to match the summaries order. Here's the current loop
for e in range(epochs):
for i, data in tqdm(enumerate(train_dataloader)):
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
art, summ = data['article'], data['highlights']
art = tokenizer(art)['input_ids']
summ = tokenizer(summ)['input_ids']
for s in summ:
s.append(EOS_token)
art_lens_desc_idx = np.argsort([len(a) for a in art])[::-1]
reverse_art_sort = np.argsort(art_lens_desc_idx)
summ_lens_desc_idx = np.argsort([len(a) for a in summ])[::-1]
art_to_summ_indexes = reverse_art_sort[summ_lens_desc_idx]
art_packed = pack_sequence([torch.tensor(art[i]) for i in art_lens_desc_idx]).to(device)
target_packed = pack_sequence([torch.tensor(summ[i]) for i in summ_lens_desc_idx]).to(device)
enc_out, enc_hid = enc(art_packed)
enc_out = unpack_sequence(enc_out)
enc_out = torch.stack([o[-1] for o in enc_out])
enc_out = enc_out[art_to_summ_indexes]
enc_hid = enc_hid[:, art_to_summ_indexes, :]
dec_out, _, _ = dec(enc_out, enc_hid, target_packed)
loss = loss_f(
dec_out.data.view(-1, dec_out.data.size(-1)),
target_packed.data.view(-1)
)
loss.backward()
enc_optimizer.step()
dec_optimizer.step()
The first sanity test we can do is try to overfit the network on a small subset of the data.
bs = 8
tmp_ds = Subset(ds['train'], list(range(8)))
train_dataloader = DataLoader(tmp_ds, batch_size=bs, shuffle=True)
Here the net basically memorizes the few examples. That's how I eventually figured out the order was wrong, since it managed to memorize the samples but the predicted summaries didn't match the targets.
Before you go
Once again I end this post in the middle. I guess I prefer to publish something than to have another half-baked draft floating around. But before you go, I did let the model train for a couple of hours on my gaming laptop. It has a 3070 GTX but it has a limited power supply. It squeezes out an iteration every second or so, which is pretty bad, and I suspect a transformer will train much faster and better. Still, after a couple of hours I got outputs the like of
Target:
Cressida Bonas went to Wembley Arena for the WE Day UK youth event.
The 24-year-old dance student dressed down in jeans and silver Converse.
Harry was key speaker, while others included Ellie Goulding, Dizzee Rascal and former footballer, Gary Neville.
Harry apologised for not being Harry Styles and said he wouldn't sing.
29-year-old prince said: 'Helping others is the coolest thing in the world'
After his 10-minute speech he joined girlfriend Cressida in the VIP seats.
12,000 students attended the London event listen to motivational speakers.
They earned their tickets to it by doing charitable acts at home and abroad.<|endoftext|>
Predicted:
Theoupleley,,, to the in for the first.....
She couple-year-old has the's in the the after has to..
She Red born to of but he to the of.. andorset and.och. her club. who..
She, for the to'by's'he would't be the<|endoftext|>But-year-old has to she 'I is'' a best'' the world'<|endoftext|>The the wifethyear-, was the,isse,, the UK of.<|endoftext|>She-000 followers with the show, in to be..<|endoftext|>The are the first to be out the a and. the. the.<|endoftext|>
Which is pretty bad. At first I thought there was a bug, but there was an improvement trend. I suspect the model which is RNN without attention has a hard time learning this task, before we even talk about optimizing hyperparameters and all the other possible things.