Today I'm recreating the learner framework from the FastAI course. It's a flexible and quite powerful abstraction around the optimization of the DNN model, which streamlines the user experience. For example, it will be very easy to add different logging capabilities, learning rate finder etc. It is built during the lesson, but there are a lot of moving parts, and a lot of usage of advanced python, which is both good and bad: good, because the code is quite elegant. Bad, because it's harder to reason about and debug, at least, that's how I feel right now. Perhaps it will change as I build it.
What is the learner abstraction comprised of?
- we break the training process
fit,fit_epochandfit_batch. - we add a callback system by emitting signals before and after each stage and calling relevant callbacks
- we use exceptions as a control mechanism for the callbacks
It's hard to say what goes where, ie how are arguments shared. Looks like the reference implementation goes all in on state, so nothing is passed as function arguments. There's even iteration with object members, eg
for self.epoch in range(n_epochs):
...
I'm creating a synthetic dataset to have something to play around with.
from torch.utils.data import Dataset, DataLoader, TensorDataset, random_split
X = np.linspace(-1, 1, num=1000)
f = lambda x: np.sin(x)
y = f(X)
ds = TensorDataset(tensor(X), tensor(y))
train, val = random_split(ds, [0.9, 0.1])
What we have so far
class Learner:
def __init__(self, model, dls, loss, lr, opt_func):
fc.store_attr()
self.opt = opt_func(model.parameters(), lr=lr)
def one_batch(self):
x, y = self.batch
self.opt.zero_grad()
y_pred = model(x)
l = self.loss(y_pred, y)
l.backward()
self.opt.step()
def one_epoch(self):
for self.i, self.batch in enumerate(self.dls.train):
self.one_batch()
def fit(self, n_epochs):
for self.epoch in range(n_epochs):
self.one_epoch()
I'm trying not to just copy-paste the code from the original notebooks, so I'm running into a lot of "design" questions. For example, how should we track the losses? we need to differentiate validation and training, we need to normalize by batch size...
Updated version:
class Learner:
def __init__(self, model, dls, loss_f, lr, opt_func=optim.SGD): fc.store_attr()
def one_batch(self):
self.xb, self.yb = to_device(self.batch)
self.preds = model(self.xb)
self.loss = self.loss_f(self.preds, self.yb)
if self.model.training:
self.loss.backward()
self.opt.step()
self.opt.zero_grad()
with torch.no_grad(): self.calc_stats()
def calc_stats(self):
acc = (self.preds.argmax(dim=1)==self.yb).float().sum()
self.accs.append(acc)
n = len(self.xb)
self.losses.append(self.loss*n)
self.ns.append(n)
def one_epoch(self, train):
self.model.training = train
dl = self.dls.train if train else self.dls.valid
for self.i, self.batch in enumerate(self.dls.train):
self.one_batch()
n = sum(self.ns)
print(self.epoch, self.model.training, sum(self.losses).item()/n, sum(self.accs).item()/n)
def fit(self, n_epochs):
self.losses = []
self.model.to(def_device)
self.ns = []
self.accs = []
self.opt = self.opt_func(model.parameters(), lr=lr)
for self.epoch in range(n_epochs):
self.one_epoch(True)
with torch.no_grad(): self.one_epoch(False)
This is now pretty much aligned with the first version in the notebook. What did we change?
- everything is basically a state variable: the batch, even the input and label of the batch, the loss, the preds.
- train/validation logic:
one_batchperforms backprop only when model is set to training. - handles device moving
- calc_stats function does all that stat tracking. keeps track of sums, when printing it calculates the weighted mean (weighted by the batch size)
- I notice now that every epoch includes previous epochs' losses and accuracies. This is not intended behavior, right?
There are some problems with our learner: first of all, the task I test on is regression, so it makes no sense to calculate accuracy, and what if we are doing autoencoding or another task without labels. Also, everything is hardcoded, so it's not easy to change stuff without creating copies.
Our next step will be to start moving things into callbacks. This will allow us to modularize some of the code.
from operator import attrgetter
class Learner:
def __init__(self, model, dls, loss_f, lr, opt_func=optim.SGD, cbs=[]): fc.store_attr()
def one_batch(self):
self.callback('before_batch')
self.xb, self.yb = to_device(self.batch)
self.preds = model(self.xb)
self.loss = self.loss_f(self.preds, self.yb)
if self.model.training:
self.loss.backward()
self.opt.step()
self.opt.zero_grad()
self.callback('after_batch')
def one_epoch(self, train):
self.callback('before_epoch')
self.model.training = train
dl = self.dls.train if train else self.dls.valid
for self.i, self.batch in enumerate(self.dls.train):
self.one_batch()
n = sum(self.ns)
self.callback('after_epoch')
def callback(self, stage):
for c in sorted(self.cbs, key=attrgetter('order')):
if hasattr(c, stage):
getattr(c, stage)(self)
def fit(self, n_epochs):
self.losses = []
self.model.to(def_device)
self.ns = []
self.accs = []
self.opt = self.opt_func(model.parameters(), lr=lr)
self.callback('before_fit')
for self.epoch in range(n_epochs):
self.one_epoch(True)
with torch.no_grad(): self.one_epoch(False)
self.callback('after_fit')
Now we added signals for before and after each stage, and a function callback that "emits" the signal, ie call every callback that listens to that signal (defined as having a method with the same name). The metrics have been moved to a callback that looks like
class Metrics:
order = 0
def after_batch(self, l):
with torch.no_grad():
n = len(l.xb)
acc = (l.preds.argmax(dim=1) == l.yb).float().sum()
self.accs.append(acc)
self.losses.append(l.loss * n)
self.ns.append(n)
def before_epoch(self, l):
self.accs = []
self.losses = []
self.ns = []
def after_epoch(self, l):
n = sum(self.ns)
print(l.epoch, l.model.training, sum(self.losses).item()/n, sum(self.accs).item()/n)
The order variable determines the order in which callbacks are called.
What's our next step? we could try out some callbacks, or make the code "nicer" with context managers, add control through exceptions or abstract some of the model calls like predict so we can support more general models.
Let's write a callback for activation monitoring. We'll use pytorch hooks. A hook is a function with the following signature
hook(module, input, output)
# registering a hook
handle = module.register_forward_hook(hook)
# remove hook
handle.remove()
We can create an abstraction that handles that for us
class Hook():
def __init__(self, m, f): self.hook = m.register_forward_hook(partial(f, self))
def remove(self): self.hook.remove()
def __del__(self): self.remove()
And then an Activations callback
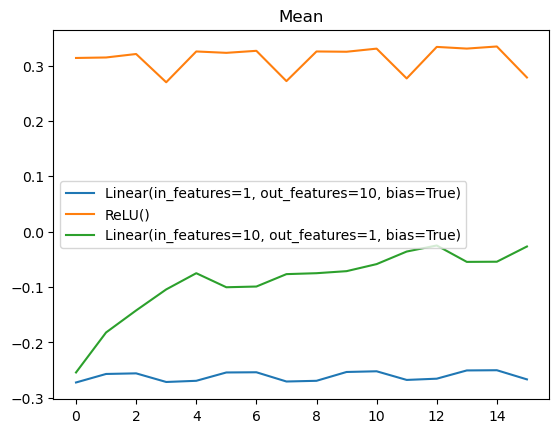
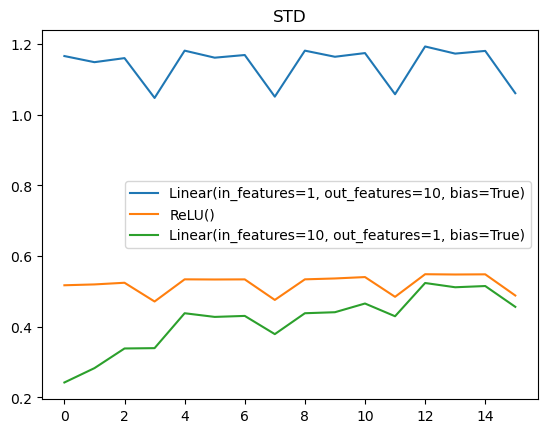
class Activations():
order = 0
def calc_stats(self, i, hook, module, inp, outp):
self.means[i].append(outp.mean().item())
self.stds[i].append(outp.std().item())
def before_fit(self, l):
self.means = [[] for _ in l.model]
self.stds = [[] for _ in l.model]
self.hooks = [Hook(m, partial(self.calc_stats, i)) for i, m in enumerate(l.model)]
def after_fit(self, l):
del self.hooks