I'm interviewing for a NLP Data Science position in a couple of days. Figured it would be fun and focusing to journal about it as I go, could be useful to peeps. Technically I already started a few days ago but now it's for real, already got the technical interview lined up, and I have 5.5 days.
I started by reading parts of Speech and Language Processing which is like the standard textbook. The 3rd edition kinda reorients itself around language modeling and the more modern stuff, which is good, but I think the company is also interested in more classical NLP knowledge as well. This is included in the second section of the book but its definitely of a different flavour (maybe because the language modeling stuff for me is more of a refresher wheres the actual NLP stuff is new). I also have [Natural Language Processing with Transformers Book](https://transformersbook.com/) which is more hands-on, but I'm not sure how deep it goes.
The company I will interview for is responsible for aspect based sentiment analysis of reviews. This is a field I don't know much about, so I thought it might be a good way to prepare, learn about it and on the way familiarize myself with the different problems one needs to solve, different models and techniques used.
Going by fast.ai philosophy, a top-down approach could be effective, where I start by learning to use the high-level tools (transformers for example) and then break it down and implement things myself. Browsing around, I found PyABSA which is an existing package for research to easily run many models on many datasets. It might be too high-level though, this is the difficulty of building your own curriculum I guess.
The PyABSA framework
This is kind of the minimal example
from pyabsa import AspectTermExtraction as ATE
aspect_extractor = ATE.AspectExtractor(checkpoint ="multilingual")
examples = ["But the staff was so nice to us."]
results = aspect_extractor.predict(text = examples) # simple inference
For which we get
[2025-10-28 16:36:09] (2.4.2) Example 0: But the <staff:Positive Confidence:0.9973> was so nice to us .
Let's let claude code look at the repo and figure out what goes on under the hood. I gave it the following prompt:
from pyabsa import AspectTermExtraction as ATE
aspect_extractor = ATE.AspectExtractor(checkpoint ="multilingual")
examples = ["But the staff was so nice to us."]
results = aspect_extractor.predict(text = examples) # simple inference
the snippet above runs the whole pipeline end to end. I want you to explore the repo, figure out what goes on under the hood in the pipeline: ie, preprocessing, tokenization,
extraction etc. Produce a document which contains the overview in three levels of depth, shallow to detailed, and include code references for everything. produce a markdown
file and save it to the folder root
It came back with a very long report. I will start with first level for now:
Claude Report
The PyABSA Aspect Term Extraction (ATE) pipeline performs two main tasks:
- Aspect Term Extraction (ATE): Identifies aspect terms in text (e.g., "staff" in "The staff was nice")
- Aspect Polarity Classification (APC): Determines sentiment for each aspect (positive, negative, neutral)
Basic Flow:
Input Text → Preprocessing → Tokenization → Model Inference → Post-processing → Results
Key Components:
| Component | Purpose | Location |
|---|---|---|
AspectExtractor |
Main inference class | pyabsa/tasks/AspectTermExtraction/prediction/aspect_extractor.py:45 |
ATEPCProcessor |
Data preprocessing | pyabsa/tasks/AspectTermExtraction/dataset_utils/__lcf__/data_utils_for_inference.py:103 |
LCF_ATEPC |
Neural network model | pyabsa/tasks/AspectTermExtraction/models/__lcf__/lcf_atepc.py:20 |
What You Get Back
{
"sentence": "But the staff was so nice to us.",
"aspect": ["staff"],
"sentiment": ["Positive"],
"confidence": [0.95]
}
End of report. So over the next few days I will need to learn about: - Preprocessing - Tokenization - Aspect Extraction - Aspect Sentiment Classification
Okay. Let's do a bit of a pivot. Let's download the Laptop14 dataset, explore it and try to build something for it. Downloading and openining the xml train file we see its consists of sentences of the form
<sentence id="2339">
<text>I charge it at night and skip taking the cord with me because of the good battery life.</text>
<aspectTerms>
<aspectTerm term="cord" polarity="neutral" from="41" to="45"/>
<aspectTerm term="battery life" polarity="positive" from="74" to="86"/>
</aspectTerms>
</sentence>
We see the data contains the result of both steps (aspect extraction and sentiment analysis). If we want to build a model, we need to formulate this as some kind of an ML problem. Nowadays, you could technically use LLMs for a lot of NLP problems (even though its not necessarily the best solution). For example, I gave this prompt to Claude
Perform ABAS on the following sentence: "I charge it at night and skip taking the cord with me because of the good battery life."
Use the following syntax as in the example below: <aspectTerms> <aspectTerm term="service center" polarity="negative" from="27" to="41"/> <aspectTerm term=""sales" team" polarity="negative" from="109" to="121"/> <aspectTerm term="tech guy" polarity="neutral" from="4" to="12"/> </aspectTerms>
And got back
<aspectTerms>
<aspectTerm term="battery life" polarity="positive" from="76" to="88"/>
</aspectTerms>
Since this is a public dataset I'm not surprised it gave back the right answer since it probably saw the input, but even though this can be seen as one way to solve it. We are interested in solving this in a ML-oriented way, and to that end we can frame the different tasks in a couple of ways (survey): - token-level tagging: we break the sentence to tokens and have the model tag which are aspects and which are not. We can use a transformer encoder like BERT to get contextual work embedding and add a classification layer to tag them. - seq2seq: a encoder-decoder approach, which will output a sequence containing the aspects. The claude answer can be thought of as such an approach. - sequence-level classification: the model will receive the sequence and an aspect and classify the sentiment. This is more relevant to the Aspect Sentiment Classification stage.
Here's an example of token-level tagging for the joint task (taken from here)
| Input | The | AMD | Turin | Processor | seems | to | always | perform | much | better | than | Intel | . |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Joint | O | B | I | E | O | O | O | O | O | O | O | S | O |
| O | POS | POS | POS | O | O | O | O | O | O | O | NEG | O | |
| Unified | O | B-POS | I-POS | E-POS | O | O | O | O | O | O | O | S-NEG | O |
And we can imagine a model like this could solve it
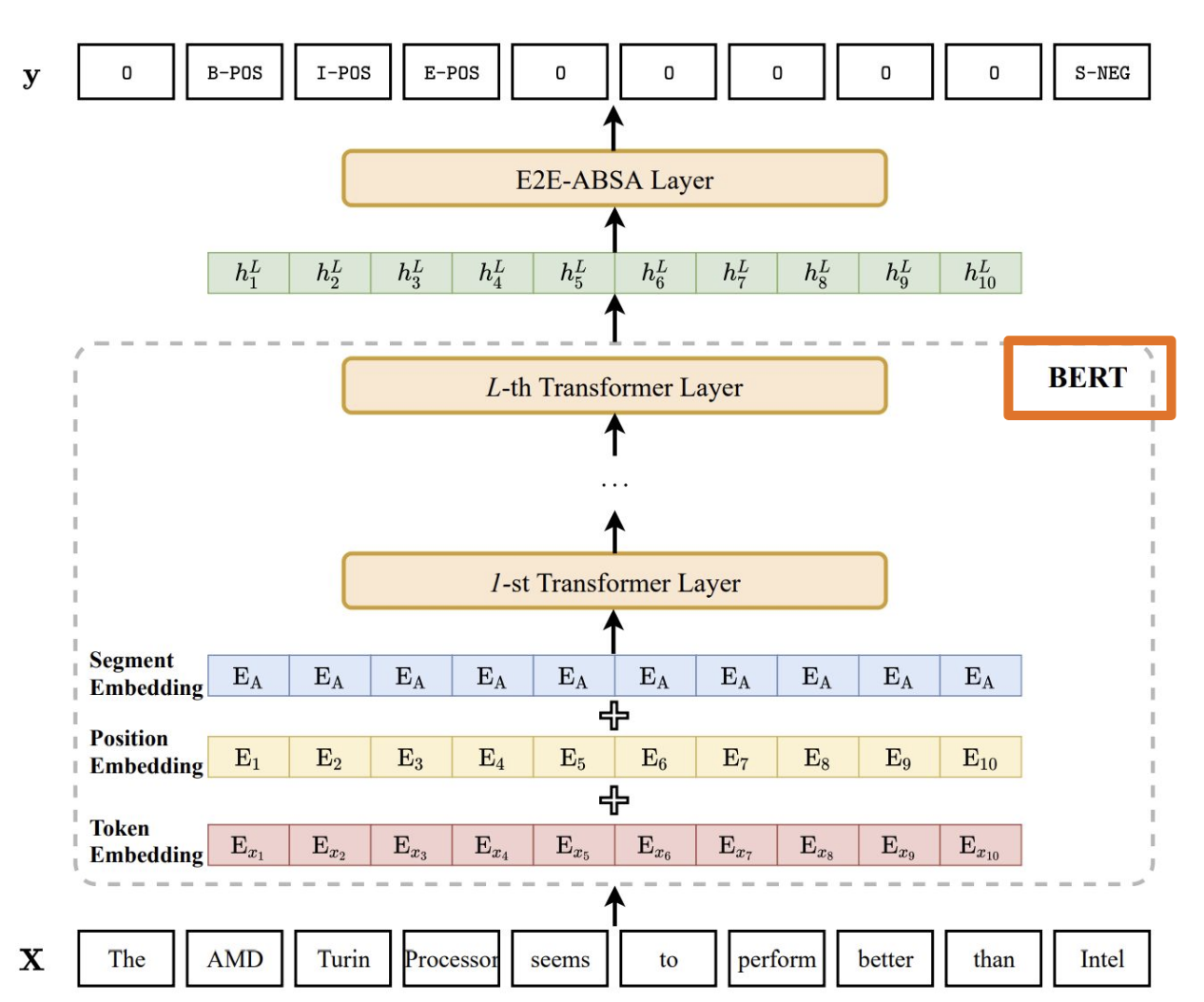
Okay. So let's regroup, what should we do? how about this: we'll remain high level today. We'll, use the transformers library to easily get a pretrained BERT model. We'll fine-tune a simple linear classification layer on top of it that classifies the aspect and the polarity (sentiment). Let's see what we can get.
First E2E Model
I'm gonna rely here on the NLP with transformers book, and reimplement the paper Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. The first stop is to get the dataset. There are several datasets on hugging face. Most are actually structured in a sentence->(aspect span, polarity) form which requires some more processing.
Here's the pipeline process from the paper:
- Loading & Parsing (glue_utils.py:_create_examples): Reads files and splits sentence/tag pairs
- Tag Schema Conversion (seq_utils.py): Converts tags to BIEOS format (Begin-Inside-End-Outside-Singleton) for precise aspect boundary detection
- BERT Tokenization (glue_utils.py:convert_examples_to_seq_features):
- Splits words into subword tokens using WordPiece
- First subword gets the original tag, rest get EQ (equivalent)
- Adds [CLS] and [SEP] tokens
- Feature Creation: Constructs input_ids, attention masks, segment IDs, and label sequences with padding
- Caching: Saves processed features to avoid reprocessing
- Training Loop (main.py):
- BERT-base-uncased (768-dim) + task-specific layer (Linear/GRU/CRF)
- AdamW optimizer, learning rate 2e-5
- Batch size 16-32, max 1,500 steps
- Saves checkpoints every 100 steps
- Evaluation: Extracts aspect-sentiment pairs from predictions and computes precision/recall/F1 metrics
Data processing
We're using the laptop14 data from the paper, which is just a text file. A row looks like this
I was looking for a mac which is portable and has all the features that I was looking for.####I=O was=O looking=O for=O a=O mac=O which=O is=O portable=O and=O has=O all=O the=O features=T-POS that=O I=O was=O looking=O for=O .=O
It tags on a word basis. The #### separates the sentence from the tagging. The data uses the Targeted Sentiment format, which basically tags a word as T-POS/T-NEU/T-NEG. I am a bit surprised by this since usually the tagging is for aspects/NERs is something like the BIESO scheme, (B-beginning, I-In, E-End, S-Singleton, O-Outside). Looking at the paper's code they actually convert the TS format to BIO. Should we do it ourselves? maybe we can start without that. Not yet sure what the drawbacks are.
Okay, I was playing around with writing the dataset abstraction in pytorch. In addition, we need to add the tokenization on top so we can feed the data directly to the model. This requires a collation function, which should also handle padding, which we will talk about next time. While doing so I started running into all sorts of parsing bugs (as one is bound to when working with data and code). I don't want to get bogged down by this, so I will have some AI look at the reference repo and reimplement something minimal and similar. Gotta choose your battles, I want tomorrow to already be training and evaluating. Anyway, signing off for now, good night folks.