Day 5
Today we'll go thru two chapters in the NLP transformers book. The first is QA, which is a task I haven't tried before and it seems interesting. There are two approaches: extractive and generative. Generative might be more common today with LLMs, since its just having the model generate an answer for the question based on the sources. Extractive QA is a little more interesting, since it has as output a substring/span of the source text, ie it highlights where in the text the response is. How do we formulate such output? my guess is with use token classification/tagging, like NER. Maybe even BIO? What kind of challenges do I forsee?
- data processing - converting the labeled string idx spans to token labels.
- Are the metrics any different? That's what I can come up with for now. In terms of data, we're gonna use the SubjQA dataset, and the electronics subset. It is a rather small dataset with about 1300 training examples, so we're definitely want to start with a pretrained model. This reflects the fact that a QA dataset is quite laborious to produce.
The important parts of the dataset for us are
- title: Amazon ASIN id
- question: the question
- answers.answer_text: the span of text in the review labeled by the annotator
- answers.answer_start: the start index of the span
- context: the review
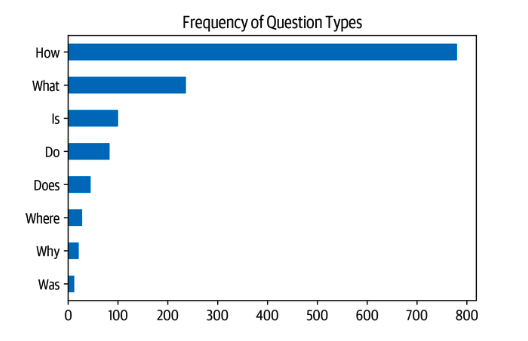
There's a nice analysis in the chapter breaking down the questions by the question word
Span classification
We frame the supervised learning problem as a span classification algorithm. As I suspected, we are using token-tagging, but we use a two class classifier that predicts whether the token is the start or end of the span. It looks something like this
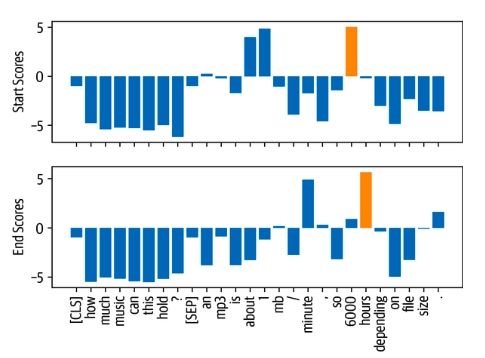
The question is how to extract the span? in the chapter they suggest taking the pair that maximizes the probability. Some possible problems: - Can get an illegal pairs (start after end) - Can have the span include the question/query - Doesn't support non-consecutive spans Not sure why its modeled this way, but apparently this is the convention.
Context overflow
Another possible problem is what happens when the source doc is larger than our context size (BERT has I think 512 tokens). A solution is to use a sliding window with some stride value and feeding each window to the model. How we then combine the candidate spans though is beyond me.
The rest of the chapter actually talks more about the QA system as a whole: a combination of retriever-reader, where the retriever is responsible for fetching relevant documents to the reader model to extract the answer model. This is actually similar to RAG so I'm gonna skip it, especially with the fact that the chapter talks more about pipeline stuff.
Claude practice
I talked with Claude about some concepts from yesterday to get some level of understanding.
- BLEU - a metric originally for machine translation. Given a reference translation and a candidate translation, you check for a couple of \(n\) how many of the n-grams in the candidate are contained in the reference. So for \(n=1\) you check whether all the words in the candidate are contained in the reference etc. Then you take an average (possibly weighted).
- LDA - Linear Dirichlet Analysis. Didn't go deep. The LDA is a graphical model for documents. It has latent "topic" variables which are word distributions, for example sports topic would have high probability for "race", "match" etc. It imagines docs being created by for each word sampling a topic and then from it sampling a word. Then you work backwards, from the "observable" words you try to infer the topics for each document. As with all bayesian methods inference is not straight-forward and requires some special algorithms. The Dirichlet comes from the priors of document-topics and topic-words.
Day 6
Last day today. I am not sure what to do. I feel like as usual I'm at the point where the theory I pretty much know but not super sharp on it, but don't want to churn it, feels kinda dry, and yet I feel like I lack some hands-on "feel", which I don't really have time to acquire. Well, whatever happens tomorrow, I think going forward I will start a habit of doing hands-on stuff, either Kaggle competitions, or follow up on some interesting project idea I have, and we'll see how it goes. For now, I upload the lectures notes and slides from CS224N to NotebookLM, and looked at some mindmaps which are pretty useful. Also tried the quizzes and flashcard features, pretty cool though still don't feel baked enough.
Why do we divide the attention score by \(\sqrt d_k\) in self-attention?
The dot product scales with dimension.This is problematic since it can lead to very spiky softmax, almost one-hot. In addition this can lead to training instability. It is a similar concept to why we want to normalize activations.
Don't know if I have time to show it today but it has to do with backprop.
ABSA
I looked back on some of the ABSA stuff today. I feel like now after studying for a couple of days I can understand better the ways BERT is used. For example, for the ASC task (Aspect Sentiment Classifcation), we formulate it is as
[CLS] sentence [SEP] aspect [SEP]
input and train a (neg, neu, pos) classifier on the [CLS] embedding, for example this model. Maybe I can reproduce the fine-tuning step on a base RoBERTa model and compare to this DeBERTaV3 model, since it is includes all sorts of tricks to boost performance.
The ATE task (Aspect Term Extraction) is then a span token classification task like we talked about before. This leaves an interesting question on the table, which is, once we have this list of aspect terms, we probably want to cluster them somehow. Now, I'm not sure if this counts as the aspect category or what, but this is an open question for me.
Finetuning RoBERTa for ASC
With the help of GPT-5 we coded a finetuning script for the task. We preprocess this dataset to fit the (sentence, aspect, polarity) form and we use the Trainer class for SequenceClassification task. Again the transformers library makes this all pretty straightforward in terms of code, and then the real world I suppose comes down to error analysis and model hyperparams.
| Model | Loss | Accuracy | Macro-F1 | Runtime (s) | Samples/s | Steps/s | Epoch |
|---|---|---|---|---|---|---|---|
| roberta-base (fine-tuned) | 0.6002 | 0.8072 | 0.7717 | 1.7235 | 370.167 | 23.208 | 4.0 |
| yangheng/deberta-v3-base-absa-v1.1 | 0.6287 | 0.8276 | 0.7902 | 3.5801 | 178.205 | 5.586 | - |
| ### Revisiting BPE | |||||||
| Reimplementing from scratch using minbpe repo. Had ChatGPT act as a tutor and breakdown the implementation to different exercises. Actually pretty neat. |