I'm pivoting the RNN summarization code to an easier example - Machine translation. Easier in the sense of the dataset, which consists of much shorter en-de sentence pairs compared to the summarization task. I have some suspicion that the there is a bug or something in my code, so today, after repurposing to the new dataset, we're gonna work on monitoring, babysitting the learning process and debugging.
Dataset
It's a pretty! big dataset. Streaming hangs me up for 30 seconds. Couldn't find a way to extract a subset nicely, so for now just saved first 1000 batches of the data loader.
Monitoring
The first and most obvious thing to track is the training loss. Here we can track the loss during the first 500 iterations. We can see that there's a clear downward trend.
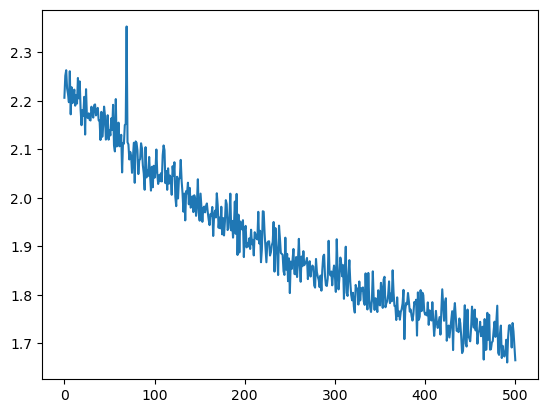
There's suppose to be a nice check one can do to verify the NN is initalized correctly. If it gives all the tokens a uniform probability then the loss should be
And indeed if we look at the output of the following snippet
x = samples[0]['translation']['en'][0]
y = samples[0]['translation']['de'][0]
x_t = torch.tensor(tokenizer(x)['input_ids'])
y_t = torch.tensor(tokenizer(y)['input_ids'])
with torch.no_grad():
eo, eh = enc(x_t.cuda())
do, _, _ = dec(eo.unsqueeze(0), eh.unsqueeze(0))
l = loss_f(do.squeeze(0)[:y_t.shape[0]], y_t.cuda())
do[0], l, np.log(len(tokenizer))
we get
(tensor([[-4.2354, -4.2840, -4.1850, ..., -4.2360, -3.9861, -4.5393],
[-4.1389, -4.1148, -4.2819, ..., -4.1094, -4.0500, -4.4847],
[-4.1877, -4.1414, -4.3016, ..., -4.2484, -3.9683, -4.3612],
...,
[-4.0528, -3.9330, -4.4955, ..., -3.9906, -4.0624, -4.5389],
[-4.0528, -3.9330, -4.4955, ..., -3.9906, -4.0624, -4.5389],
[-4.0528, -3.9330, -4.4955, ..., -3.9906, -4.0624, -4.5389]],
device='cuda:0'),
tensor(4.1989, device='cuda:0'),
4.189654742026425)
The first item is the log-distribution for an output token which is pretty much uniform, next is the CE loss and third is the log of the size of the vocabulary, and indeed things match.
Also, regarding tokenization: I switched to character level tokenization to make things simpler. Well, it's almost simpler. Now we have a bit of a different behavior, where characters not in the vocabulary are replaced with the unknown token.
Now I'm playing around with the training. I'm logging the loss, I also added the gradient norm for the encoder and decoder. I read a bit of Karpathy's blog post about RNNs, looking for some training tips. I settled for 2 GRU layers with a hidden size of 512, batch size of 128, adam with learning rate of 2e-3 and exponential decay of 0.95 every 500 steps. Here's a graph. It's not from the start as can be see since the beginning lose isn't ~4. The orange line is a smoothed graph, the edges have some boundary artifacts though.
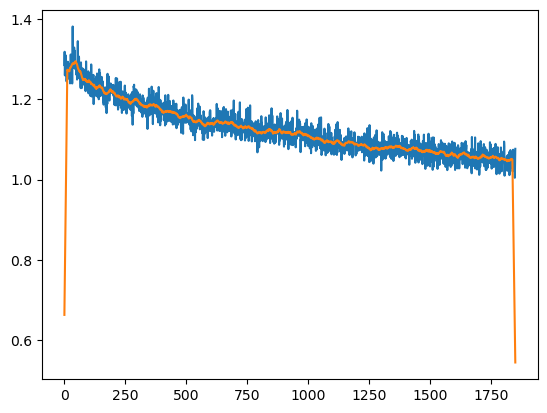
The thing bothering me now is that in the blog post, Andrej says that within 300 iterations it was already quite coherent, and I'm still getting stuff like
English:
[CLS]Despite the different cultural and geographical conditions within Asia, the conference revealed once more that Asian nations often face the same or similar challenges.[SEP]
Target:
[CLS]Trotz der unterschiedlichen kulturellen und geografischen Gegebenheiten innerhalb Asiens verdeutlichte die Konferenz einmal mehr, dass sich die asiatischen Nationen oft gleichen oder ähnlichen Herausforderungen gegenübersehen.[SEP]
Predicted:
[CLS]Drotz der Sngerschiedlichen Sorturellen und drsgrafischen Seseneneeit n dn erhalb drien dorwinteich endie Momterenz dineal dihr diss dieh die Mniatische Samionen ddf deaichzr ader ahnlich r Rärausforderungen uesen ber tten [SEP]
Now, it could be because I'm using a seq2seq model and he uses just a decoder, but there could also be a bug in the code... or some bad configuration, or maybe that task is harder? who knows. I don't have a lot of intuition for how to debug this.
After 10000 iterations, loss is down to 0.9 but translations are still weird
Target:
[CLS]Übrigens hat Jen das Herz dieses Schriftstellers bereits gewonnen, indem sie im nationalen Fernsehen enthüllt hat, dass sie, Ben und die Kinder alle hatten Kopfläuse vor ein paar Jahren.[SEP]
Predicted:
[CLS]Ibeigens JattJasnJis Jarz geeser Jphöittsteller geseits gesonnen, dn em sie dn Bäcionalen Barnsehen grtwallt uabt uass die uer und dee Binder aulesaabten eanf.infeneer.dineJaar Jahre..[SEP]
The question is how much to push the vanilla rnn without adding attention. Well, next time I'm going to go back to school and go over some fast.ai lectures.